
What is RAG? (Retrieval-Augmented Generation)?
RAG is an artificial intelligence technique that optimizes the output quality of large language models. The system consults authoritative knowledge bases outside the model’s training data before generating a response. Its basic logic is to combine the processes of information retrieval and text generation. While traditional language models rely only on the information they learn during the training phase, RAG dynamically pulls information from external data sources. This approach allows new information to be incorporated into the system without retraining the model. Sources such as corporate documents, current news, technical manuals, or databases can be used as knowledge bases.
Thanks to RAG, artificial intelligence applications produce sector-specific, up-to-date, and verifiable responses. It plays a critical role, especially in areas such as customer service, technical support, and information management. With the widespread adoption of generative AI solutions, RAG has become a cost-effective method that allows businesses to get maximum value from their AI investments. The ability to update the knowledge base instead of retraining the model makes this technology particularly attractive.
How Does Retrieval-Augmented Generation Work?
Retrieval-Augmented Generation (RAG) is an approach that allows artificial intelligence models to extract relevant information from external data sources and incorporate it into the response generation process, instead of relying solely on training data. The system first finds the most relevant documents for the question (retrieval), then uses this information as context to generate a more accurate, up-to-date, and reliable answer (generation).
The RAG architecture basically works in four stages:
1-Data Preparation (Indexing) : Texts from external sources are converted into numerical vectors (embeddings) and saved to a database.
2-Information Retrieval : When the user asks a question, the system selects the most relevant content from the database.
3-Information Augmentation : The selected content is presented to the model as additional context.
4-Response Generation : The model generates a response using both the data it was trained on and the retrieved information. Thanks to this structure, it is possible to use new and up-to-date information without retraining the model.
How Does RAG Technology Work?
RAG systems consist of two main components: information retrieval and response generation. This process begins with a user query and continues with a multi-layered workflow.
In the first stage, external data sources are prepared. Data in different formats such as corporate documents, database records, API responses, or web pages are collected. This data is converted into numerical vectors using embedding models. Vector representation allows artificial intelligence models to mathematically understand and compare text content. This converted data is stored in vector databases and made ready for quick access.
When a user asks a question, the query is also converted into a vector. The system compares the query vector with all vectors in the database to find the most relevant pieces of information. This comparison is usually done using mathematical methods such as cosine similarity. For example, when an employee asks, “What is our annual leave policy?”, the system can retrieve both general leave policy documents and the employee’s personal leave records.
After the information retrieval stage, the relevant information found is combined with the user query. This augmented input is fed into a large language model. The model uses both general information from its training data and newly introduced specific information to produce a consistent and accurate response. Throughout the process, requests engineering techniques are used to ensure the model operates optimally.
Automatic update mechanisms are implemented to keep the knowledge base up-to-date. When documents change or new information is added, vector representations are recalculated. This process can be done in real-time or in batches at specific intervals. Thus, the system has continuous access to up-to-date information.
Working Principle of RAG Architecture
The RAG process consists of three main stages:
- Retrieval: The most relevant data pieces related to the user’s question are queried from the vector database.
- Augmentation: The obtained information is added to the user’s original question, providing the model with rich context.
- Generation: The model produces an error-free response based on this specific evidence presented to it.
What are the Advantages of RAG?
- Access to up-to-date information
- More accurate and contextual responses
- Updating information without retraining the model
- Enterprise data integration
- Generating a citable response.
How is RAG Used in Enterprise Artificial Intelligence?
Corporate companies use RAG in the following areas:
- Internal Document Chatbots
Provides employees with quick access to internal company documents.
- Customer Support Automation
Creates intelligent response systems connected to product databases.
- Legal Information Systems
Generates accurate information from regulatory and legislative texts.
- Data Analytics Supported Reporting
Generates contextual interpretations from real-time data sources.
History of the RAG Model
The Retrieval-Augmented Generation (RAG) model emerged from the work of Facebook AI Research (FAIR) researchers – now META AI – (Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela).
RAG (Retrieval-Augmented Generation) is a term introduced in 2020 in an article titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. The history of this model has been shaped by the development of this technology and the advancement of integration between knowledge retrieval and language processing.
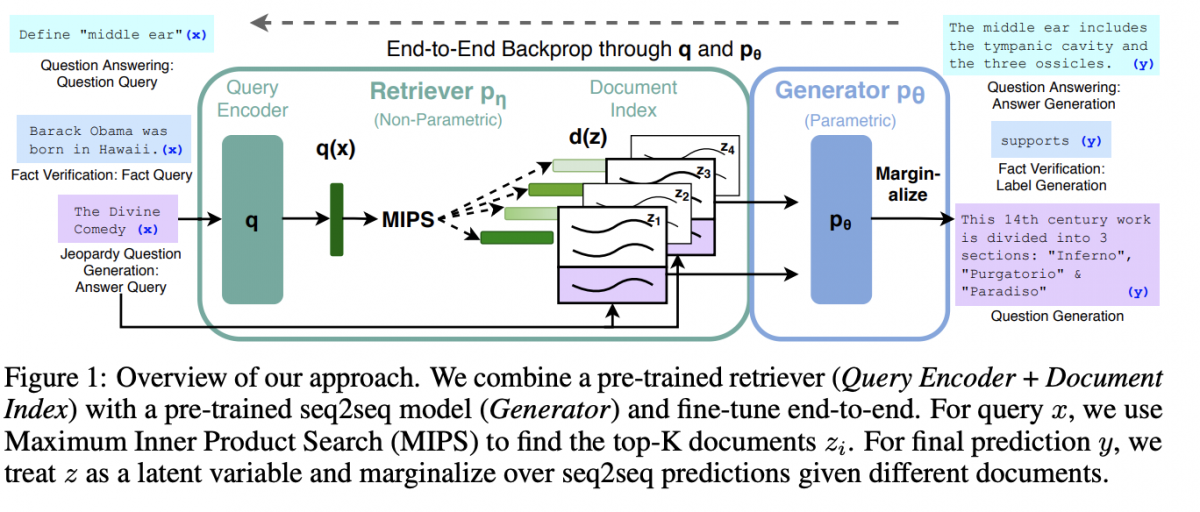
How Does the RAG Model Work?
Now, let’s assume a user sends a specific information query to a generative AI system; for example, “How many matches has the Turkish Women’s National Volleyball Team won, who are the team players, and when is the next match?” Here, the queries are converted into a vector and used to query the vector information source, which retrieves context-related information about the question. When users ask a question to an LLM, the AI model sends the query to another model, converting it into a numerical format that machines can read. The numerical version of the query is sometimes called “embedding” or “vector.” The embedded model then compares these numerical values to vectors in a machine-readable index in an existing information source. When it finds a match or multiple matches, it retrieves the relevant data, converts it into words that humans can read, and sends it back to the LLM.
Finally, the LLM combines the received words and its own response to the query into a final response presented to the user, creating a text response.
What is the Difference Between NVIDIA and RAG?
NVIDIA uses open-source libraries like LangChain in its artificial intelligence (AI) development and implementation processes, especially in conjunction with RAG models. LangChain is considered a library that can help developers in areas such as connecting LLMs, bringing together different models, and integrating knowledge bases.
NVIDIA uses these libraries to support developers in creating AI projects and building complex AI systems, such as RAG models, more effectively. In particular, training is offered through platforms like NVIDIA LaunchPad Lab to teach and provide experience to developers in applications such as AI chatbots and RAG-based models.
Such initiatives offer developers opportunities to develop and implement various projects using new and complex AI structures like the RAG model. Large technology companies like NVIDIA support development in this field by providing training and resources to encourage advancements in areas such as AI and RAG and to ensure the adoption of these technologies.
RAG and Large Language Models (LLM)
Now, let’s consider that an end-user sends a specific command to a generative AI system. For example, “Where is tonight’s game being played, what lineups will be starting, and what are the reporters saying about the match?” The query is converted into a vector and used to query the vector database, which retrieves information relevant to the context of the question. This context-based information, plus the original command, is fed into the LLM, which generates a text response based on both partially outdated general information and highly current and contextually relevant information.
Interestingly, while the generalized LLM training process is time-consuming and costly, updates to the RAG model are the opposite. New data can be loaded into the embedded language model and continuously and incrementally converted into vectors. In fact, responses from the entire generative AI system can be fed back into the RAG model, improving the model’s performance and accuracy because the model knows how it has answered a similar question before.
An additional advantage of RAG is that the generative AI can provide the specific data source included in the response using the vector database. LLMs cannot do this. Therefore, if there is an error in the output of generative AI, the document containing the erroneous information can be quickly identified and corrected, and then the corrected information can be fed into the vector database. In short, RAG provides evidence-based timeliness, context, and accuracy to generative AI, going beyond what an LLM can provide on its own.
Retrieval-Augmented Generation – Semantic Search Comparison?
RAG is not the only technique used to improve the accuracy of LLM-based generative AI. Another technique is semantic search, which helps the AI system narrow down the meaning of a query by trying to understand specific words and phrases in the command in depth.
Traditional search focuses on keywords. For example, a basic query about tree species native to France might allow an AI system to search its database using “trees” and “France” as keywords and find data containing both keywords. However, the system might not truly understand the meaning of “trees in France” and therefore retrieve too much, too little, or even incorrect information. Because keyword search is very fixed-value, information may be missing from the search: trees native to Normandy, although also in France, might be overlooked because this keyword is missing.
Semantic search goes beyond keyword search by determining the meaning of queries and source documents and using that meaning to obtain more accurate results. Semantic search is an integral part of RAG.